In 1980, an 18 year old named Willie Ramirez arrived unconscious at a Florida hospital. His family described him in Spanish as “intoxicado,” a word that in Cuban usage points to something he had eaten or drunk. Staff heard “intoxicated” and treated him for a drug overdose. He was in fact suffering an intracerebral haemorrhage that went untreated for days. He was left quadriplegic, and the case settled for roughly 71 million dollars. One false friend, one wrong branch of meaning, and a life changed forever.
Four decades on, the interpreter sitting in many clinical and administrative workflows is software. The false friend problem did not disappear. It moved.
The Single Point of Failure
Why standardising on one model quietly concentrates risk
Most digital health teams that reach for machine translation pick one engine and standardise on it. It is the natural decision: one tool, one integration, one invoice. The hidden assumption underneath it is that the tool produces the translation, as if a single correct output were sitting there waiting to be retrieved.
It is not. Every AI model carries its own training data and its own habits around negation, dosage, frequency and clinical shorthand. Ask it to render “as needed” or “do not exceed” and each model resolves that ambiguity slightly differently. When you depend on one engine, you inherit that engine’s specific blind spots, and you never see the alternatives it quietly discarded. It is the same accountability gap that surfaces whenever a digital health tool gets something wrong: by the time anyone notices, the output already looks authoritative.
The Test
One discharge instruction, four outputs
To make this concrete, take a routine discharge instruction and run it through four widely used AI models, then read each result back into English. The wording below is representative of how these systems diverge on clinically loaded phrasing.
“Take one tablet by mouth every six hours as needed. Do not take more than four tablets in twenty four hours.”
| Model | How the meaning came back | What shifted | Risk |
|---|---|---|---|
| Model A | “Take one tablet by mouth every six hours as needed. Do not take more than four tablets in 24 hours.” | Nothing material. PRN qualifier and ceiling both intact. | Low |
| Model B | “Take one tablet by mouth every six hours. Do not take more than four tablets in 24 hours.” | Dropped “as needed.” Turns flexible dosing into a fixed schedule. | Moderate |
| Model C | “Take one tablet every six hours when needed. Try not to take more than four tablets a day.” | Softened the negation. A hard ceiling becomes a suggestion. | High |
| Model D | “Take one tablet by mouth every six hours as needed. No more than four tablets per day.” | “In 24 hours” became “per day.” Subtle, but not identical for split dosing. | Moderate |
Table 1. Four models, one source sentence, four readings. The text never changed. The clinical meaning did. Renderings are illustrative of documented divergence patterns in AI medical translation.
The Data
This is measurable, not anecdotal
A comparative analysis published in the peer reviewed literature put two AI models, GPT 4 and Google Translate, through 316 real emergency department instruction sentences across Spanish, Chinese and Russian. At the sentence level the gap between models looked modest.
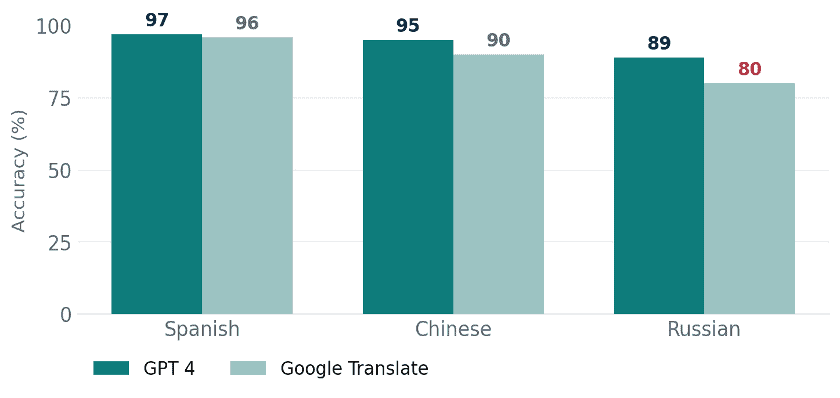
Figure 2. At sentence level both tools clear 90 percent for Spanish and Chinese, but Russian exposes a real gap. Source: peer reviewed comparative analysis of patient discharge instructions.
The reassuring part stops there. Once you stop counting individual sentences and start counting whole instruction sets, meaning the complete document a patient actually receives, the divergence widens sharply.
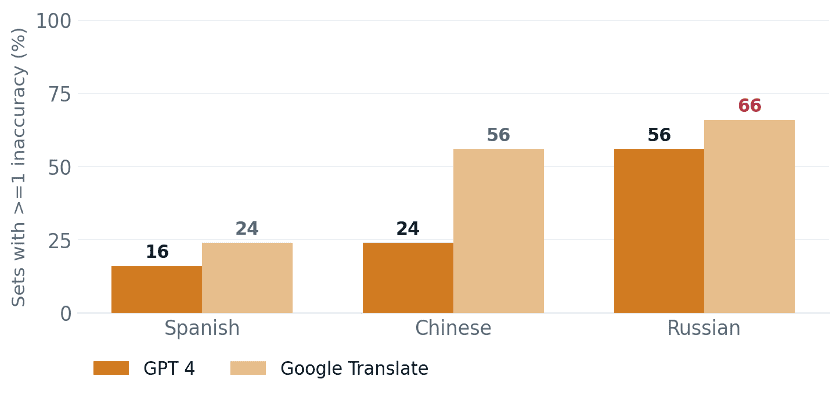
Figure 3. The same two tools at document level. Up to 66 percent of Russian instruction sets carried at least one inaccuracy, and the distance between the two models grew with every harder language. Model choice is not a rounding error. It compounds.
The Reframe
Divergence is the signal, not the noise
Here is the shift in thinking. The disagreement between models is usually treated as a nuisance to be hidden behind a single, confident output. It is actually the most useful diagnostic you have. When several independent models agree on a clause, confidence in that clause is high. When they split, you have just been handed a precise map of exactly where a human reviewer should look first.
That principle is the basis of a multi model, consensus based approach to AI translation. Instead of trusting one engine, you run the same text through many and surface the rendering they agree on, while flagging the clauses where they part ways. One AI translator, MachineTranslation.com, applies this directly: it routes a single input through 22 AI models, returns the consensus output, and makes the points of disagreement visible rather than burying them. The agreement becomes the quality signal. The disagreement becomes the review queue.
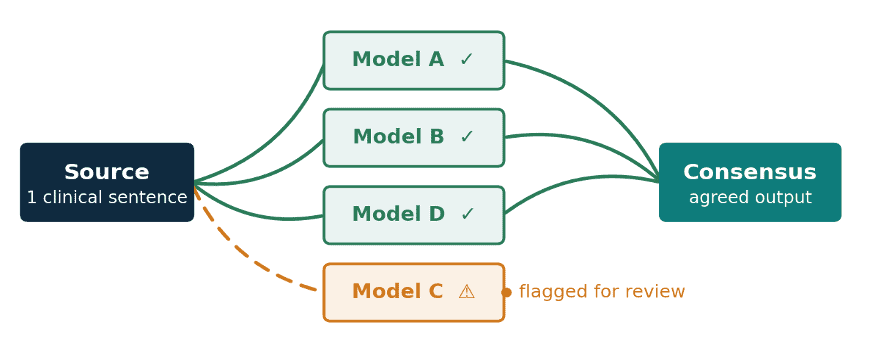
Figure 4. The clauses every model agrees on ship with high confidence. The clause one model renders differently is exactly the one a clinician or professional translator should see.
In medicine the dangerous output is not the one that is obviously wrong. It is the one that reads perfectly and means something slightly different. Comparing models is how you catch the second kind before a patient does.
Ofer Tirosh, CEO, translation company Tomedes
For Practice
What this means for digital health teams
- Treat single engine output as a draft, never a verdict, for any clinical or regulated content.
- Use model disagreement as triage. Where outputs split, that is where human review time should go first.
- Match the workflow to the stakes. Low risk patient facing content tolerates more automation. Dosage, consent and adverse event language does not, and the study authors themselves recommend professional review for high stakes text.
- Keep the source and a back translation in the loop, so a shift in meaning is visible to someone before it reaches a patient.
The Ramirez case is remembered because the cost was so visible. The everyday risk is quieter: a softened negation, a dropped “as needed,” a frequency that slips from “per 24 hours” to “per day.” No single model is built to catch all of these, because each one is, by design, one opinion. The safest answer in clinical translation is rarely the loudest single output. It is the one that several independent models, and a human, can all stand behind. As AI moves deeper into healthcare, that distinction is going to matter more, not less.
Digital Health Buzz!
Digital Health Buzz! aims to be the destination of choice when it comes to what’s happening in the digital health world. We are not about news and views, but informative articles and thoughts to apply in your business.


